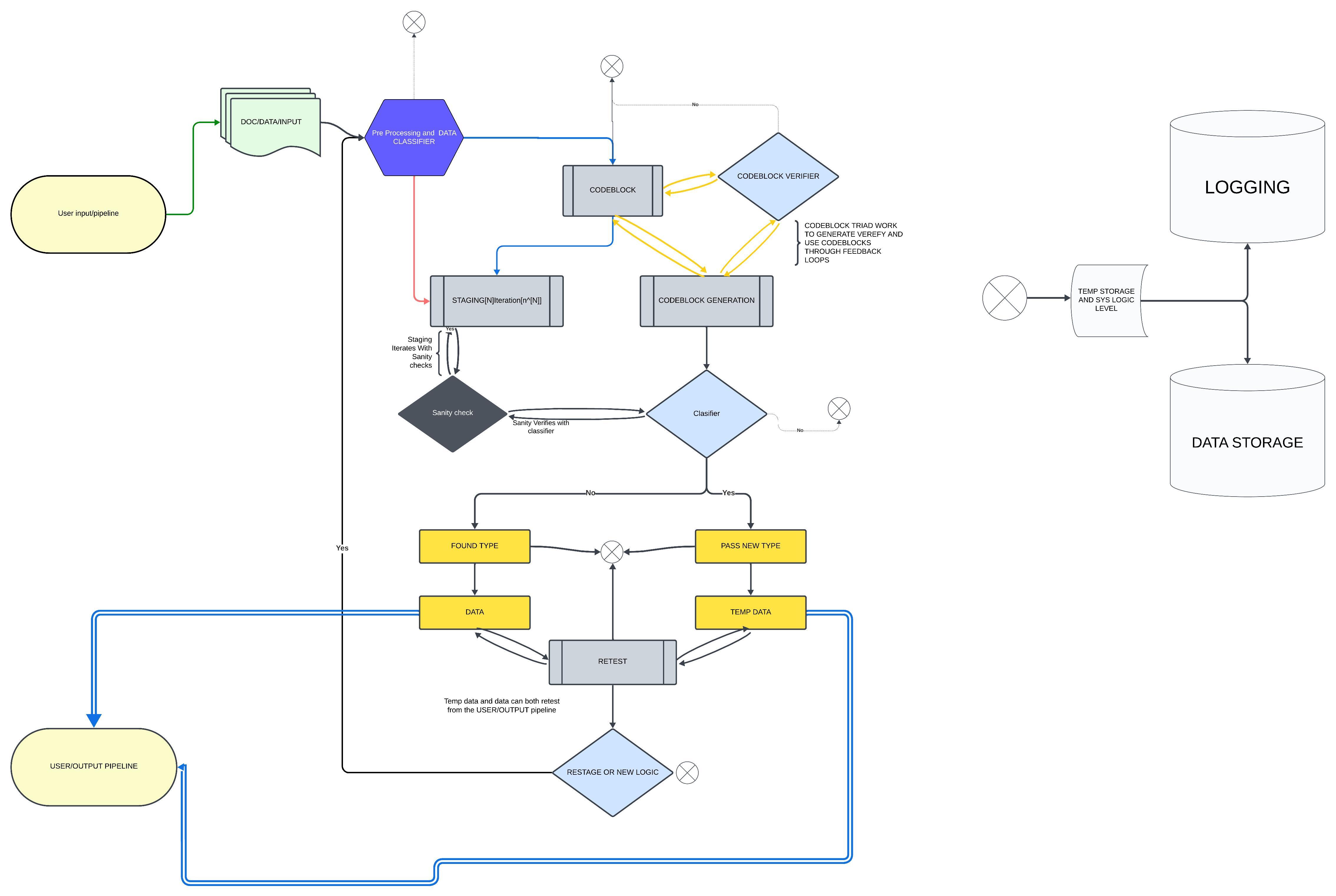
Progress and Concepts
1. **Hybrid Database System**:
- We’ve decided to move forward with a **self-organizing hybrid database** that combines both **data** and **code**.
- The database dynamically processes, links, and optimizes stored data with codeblocks like `INCODE`, `OUTCODE`, `THROUGHCODE`, `JOINCODE`, and more.
2. **Rotary Structure**:
- We conceptualized a **rotary-inspired structure** where:
- A “spindle” rotates to classify words based on their **position** and **type**.
- This creates **unique patterns** that enhance sentence structure matching and response generation.
3. **Dynamic Codeblocks**:
- Codeblocks allow data entries to contain their own **logic pathways**.
- Examples:
“`json
“INCODE”: “while(weight < 0.9) { Pairs { infer pairs to semblance of input } }"
"CODEBLOCK": "JOINCODE: INPUT[UUID 18 through 17,3,47,119]"
```
4. **Sentence Parsing and Structure Mapping**:
- Using sentence structure patterns like:
“`text
(S (NP) (VP (NP)))
“`
- This helps to match input sentences quickly and accurately across the database.
5. **Libraries Integrated**:
- **Preprocessing**: `compromise`, `franc` (language detection).
- **Sentiment Analysis**: `vader-sentiment`.
- **Intent Analysis**: `brain.js`.
- **Entity Extraction**: `TaffyDB`.
- **Semantic Analysis**: Placeholder for external LLaMA models.
6. **Project Folder**:
- New test folder: **`TEST-A`** for running various nested callback tests.
- JavaScript file: **`Spindal1.js`** for integrating all the libraries and testing sentence processing.
### Next Steps
- **Debug and Fix Issues**:
- Resolve errors with TaffyDB and dynamic imports.
- **Test Rotary Mechanism**:
- Implement and test the rotary system for classifying and linking words.
- **Optimize Database**:
- Add more codeblocks and refine database mechanics for efficiency.
🌀 Iterative Spindle Processing System
🔄 Iteration Flow
First Iteration:
Initial Mapping: Rotate through the sentence to create a basic skeleton.
Skeleton Matching: Check if this skeleton exists in the database.
Action:
Use Existing Skeleton if a match is found.
Create New Skeleton if no match exists.
Second Iteration:
Token Processing:
Extract tokens, POS tags, sentiment, intent, and entities.
Metadata Attachment: Attach these to the sentence structure.
Database Integration:
Store the Sentence: Save the skeleton, tokens, and metadata to the database.
Trigger Codeblocks: If the sentence matches certain criteria, trigger relevant codeblocks inside the database to perform actions like linking data, executing functions, or optimizing storage.
🛠️ Detailed Steps and Code Example
1️⃣ First Iteration – Create and Match Skeleton
function generateSkeleton(words) {
return `(S ${words.map(word => mapPOS(word.POS)).join(" ")})`;
}
function mapPOS(POS) {
const mapping = {
Noun: "(NP)",
Verb: "(VP)",
Adjective: "(ADJP)",
Adverb: "(ADVP)"
};
return mapping[POS] || "(X)";
}
function firstIteration(sentenceWords, spindle) {
const skeleton = generateSkeleton(sentenceWords);
const result = spindle.rotate(sentenceWords);
if (result.action === "create") {
spindle.addSkeleton(result.skeleton);
}
return skeleton;
}
// Example sentence
const sentenceWords = [
{ word: "Lexx", POS: "Noun" },
{ word: "runs", POS: "Verb" },
{ word: "fast", POS: "Adverb" }
];
const skeleton = firstIteration(sentenceWords, spindle);
console.log("Skeleton:", skeleton);
Output:
Skeleton: (S (NP) (VP) (ADVP))
2️⃣ Second Iteration – Extract Tokens and Metadata
In the second pass, attach metadata like sentiment, intent, and entities.
function secondIteration(sentence) {
const sentimentScore = analyzeSentiment(sentence);
const intent = analyzeIntent(sentence);
const entity = extractEntities(sentence);
return {
sentiment: sentimentScore,
intent: intent,
entity: entity
};
}
// Example usage
const sentence = "Lexx runs fast.";
const metadata = secondIteration(sentence);
console.log("Metadata:", metadata);
3️⃣ Database Integration and Codeblock Triggering
When storing the sentence, we can attach codeblocks that get triggered based on specific conditions.
const database = [];
function storeInDatabase(skeleton, metadata) {
const entry = {
skeleton: skeleton,
metadata: metadata,
codeblock: "JOINCODE: LINK [UUID 18 through 17,3,47,119]"
};
database.push(entry);
}
// Store the data
storeInDatabase(skeleton, metadata);
console.log("Database Entry:", database);
🔥 Flow Recap
Rotation:
Spindle rotates over the sentence and creates a basic mapping skeleton.
Token and Metadata Extraction:
Extract POS tags, sentiment, intent, and entities.
Database Storage:
Store the sentence skeleton and metadata in the database.
Attach and trigger codeblocks dynamically within the database.